Top Download Media Supplement Language Data Database Tips Database Files Phylogenetics Files Background Controversies Reading All Authors
Welcome to the support page for …
Language trees with sampled ancestors support
a hybrid model for the origin of Indo-European languages
To download the paper free,
please go to the IE-CoR database
and use the link at the start of the home page.
Heggarty et al. (2023) in Science
doi: 10.1126/science.abg0818
Published 28 July 2023. BibTeX file here.
Full list of all 33 authors and personal webpages.
1. Download the Article Free
To download the article free, please go to the IE-CoR database and use the permitted link at the start of the home page. Thanks!
The full article is 10 pages, only online as a pdf. , and includes at the start the 1-page summary in the print edition of Science.
Please also explore iecor.clld.org, our language database, and our Supplementary Materials, where we directly address the many controversies about Indo-European origins and phylogenetic analyses.
2. Media Interest and Popular Science Articles
This paper has been reported on in Science news, New Scientist, El País (in Spanish and in English), Frankfurter Allgemeine, the Telegraph of India, the Globe & Mail (Canada), Gazeta Wyborcza, (Poland) and the History First blog, among others.
For a fuller list of coverage also on social media (Twitter, Facebook, etc.), see Altmetric.
Science correspondents have a challenging task to cover a vast range of different sciences, and to explain complex issues as straightforwardly as possible for a non-specialist public. Specialists might not always agree with how press stories express everything, even when ‘citing’.
3. Supplementary Material
Two supplementary text files are freely available at Science, as pdfs:
- The Guide to Data and Results Files, to help explore and reproduce our results.
- The main Supplementary Materials for the paper (c. 100 pages of full background and detail on our database methodology and phylogenetic analyses).
We also make available the full files of our language data, and our phylogenetic analyses, as detailed in 6 and 7 below.
4. Explore the IE‑CoR Language Database Online
Please explore iecor.clld.org, by far the best and fastest way to get an understanding of the language data we analysed and that underlie our phylogenetic results. IE‑CoR is our database of Indo-European Cognate Relationships in ‘core’ vocabulary, 170 reference meanings in which words are generally more stable than in most meanings.
The screenshot below shows (by colours) the patterning of shared word roots in the primary term for the sample meaning FIRE across the 109 modern languages (round dots) and 52 ancient or historical languages (diamonds) in our database.

Note at the bottom of the screenshot the link to the IE‑CoR Definition, tailored for each meaning. To avoid a major methodological problem with past cognate databases (see Heggarty (2021)), IE‑CoR follows its own precise definition of a specific target sense (of the word ‘fire’ in English, as the meta language used as the label for its reference meanings).
On IE‑CoR you can view the data for one or more individual languages, or individual meanings, or explore all or any one of the 5013 different cognate sets (i.e. sets of related words, which go back to a single ancestral form).
For each meaning there is a map of how different cognate sets pattern across the various major branches of the Indo-European family. For an instant idea, click compare these Illustrative examples:
- FOUR: almost all dots are the same colour, since this is a deep Indo-European word root surviving in almost all languages, except for occasional ‘reborrowings’ (e.g. in Balochi: Sistani, borrowed from Persian).
- FIRE: various cognate sets, including two main ones distributed across different branches of Indo-European. Note also this example of where the primary term in all spoken Romance languages (derived from focus, as reconstructable to Proto-Romance) is not cognate with the primary term in written Classical Latin (ignis).
- TOOTH: also two deep cognate sets, but one much more widespread than the other.
- DIRTY: a meaning in which turnover of different words, and thus cognate sets, is unusually fast, so there is a wide scatter of many different cognate sets across the map.
5. Tips on Using, Citing and Linking to the IE‑CoR Database
Attentive readers may have noticed in reference 37 of our paper that IE‑CoR permits a simple search syntax to create custom URLs to go direct to one or more filtered subset of data in any given table/view.
For example, to compare any two languages, such as Early Vedic and Younger Avestan, the URL is:
https://iecor.clld.org/values?sSearch_3=Avestan:+Younger,Vedic:+Early
This is equivalent to selecting the languages manually from the drop-down box under the languages column on the lexemes page. Similar custom URLs can be created for other subsets of the data, on other pages too.
The syntax for such URLs is:
- The path for the IE‑CoR root: https://iecor.clld.org/
- The view/table required: e.g. languages, cognatesets, parameters (i.e. meanings) or values (i.e. lexemes).
- The filter query syntax: ?sSearch_ (don’t forget the trailing underscore).
- The number of the column to be searched in on that page — in this example, column 3 (language name).
- An equals sign =
- The entry to be searched for in that column, in URL form, including punctuation (often, a colon : ), and using + for any spaces, e.g.: Avestan:+Younger
- To search for multiple entries in the same column, separate the entries with a comma , without any spacing, e.g.: Avestan:+Younger,Vedic:+Early
Hence https://iecor.clld.org/values?sSearch_3=Avestan:+Younger,Vedic:+Early
As further illustrative examples:
- Early Vedic compared against Hindi:
https://iecor.clld.org/values?sSearch_3=Vedic:+Early,Hindi - All five forms of Kurdish in IE‑CoR:
https://iecor.clld.org/values?sEcho=2&sSearch_3=Kurdish+S.:+Qorveh,Kurdish+S.:+Elami,Kurdish+C.:+Jafi,Kurdish+N.:+Bahdini,Hawrami - All three varieties of Albanian in IE‑CoR:
https://iecor.clld.org/values?sEcho=2&sSearch_3=Albanian:+Standard,Albanian:+Gheg,Albanian:+Arb%C3%ABresh - All 1604 cognate sets for which the IE‑CoR reference language (column 3) is Proto-Indo‑European:
https://iecor.clld.org/cognatesets?sSearch_3=Proto-Indo-European - All 4 cognate sets across different IE‑CoR reference meanings (HEAR, KNOW, SAY, SEE) that in fact reflect the same IE‑CoR cognate ‘superset’ (304), derived from Proto-Indo-European *u̯ei̯d- (the IE‑CoR reference form in column 2):
https://iecor.clld.org/cognatesets?sSearch_2=*u̯ei̯d- - All 1039 cognate sets of the loan event type (column 6):
https://iecor.clld.org/cognatesets?sSearch_6=True - All 187 cognate sets of the loan event type and also the parallel loan subtype of those (column 7):
https://iecor.clld.org/cognatesets?sSearch_7=True
It is also possible to create URLs for custom combinations of languages and meanings. This can be done from the Lexemes page (i.e. /values) by a URL including search terms to filter both the languages column [ &sSearch_3= ] and the meanings column [ &sSearch_1= ]. As examples:
- To filter down to the words in these two Germanic languages, five Romance ones, and Ancient Greek, in the meaning FIRE:
https://iecor.clld.org/values?sEcho=2&sSearch_3=English,German,Latin,Portuguese,Spanish,Catalan,French,Greek:+Ancient&sSearch_1=fire - To filter down to the words in these two Germanic languages, five Romance ones, and Ancient Greek, in six meanings:
https://iecor.clld.org/values?sEcho=2&sSearch_3=English,German,Latin,Portuguese,Spanish,Catalan,French,Greek:+Ancient&sSearch_1=fire,five,tooth,tongue,hand,foot
6. Download the IE‑CoR Language Database Files
For computational processing rather than browsing, you can also download the raw data tables that underlie IE‑CoR.
- To download only small subsections of the database, various IE‑CoR pages include a link to download only the table underlying whichever page is being viewed.
- To download all files together, click on: https://doi.org/10.5281/zenodo.8089434
7. Reproduce or Explore the Phylogenetic Analysis: Full Data, Analysis and Results Files
To explore or reproduce our phylogenetic analyses, follow the:
- The Guide to Data and Results Files, and …
- Section 5.5 of the Supplementary Materials, on the “Pipeline: from the IE-CoR Database to Beast Input Files”.
All input data, analysis and results files can be downloaded together as zips from
https://doi.org/10.5281/zenodo.8147476.
Alternatively, they can be browsed and downloaded individually from
https://share.eva.mpg.de/index.php/s/E4Am2bbBA3qLngC.
The Guide also gives links to where all software used can be freely downloaded.
8. Background: The Indo-European Debate Since Language Phylogenetics and Ancient DNA
Much of the background and contentious issues in phylogenetic analyses of Indo-European languages, and ancient DNA, can be read in Sections 1 and 2 of the Supplementary Materials.
Further background will be provided here soon …
9. Main Controversial Issues
Indo-European origins, and the application of Bayesian phylogenetic methods to cognate data from language families, are both highly contentious, with a whole series of controversies in each. Likewise, there is much debate and some controversy in interpreting the ancient DNA record with respect to various branches of Indo-European: which past population movements inferred from ancient DNA might be the best candidates for explaining the spreads of which branches of Indo-European?
Necessarily we take up these issues in our paper, and especially in the supplement where much more space is available to discuss them. We refer here repeatedly to the corresponding sections in the supplement, and to sensitivity analyses (SAs) that we performed specifically to investigate them. For references cited here, for now please see the references section of the supplementary analysis (direct links will be provided here soon).
On the Indo-European question, controversies surround arguments in favour of the Steppe hypothesis, each of which has however been challenged. Among these are …
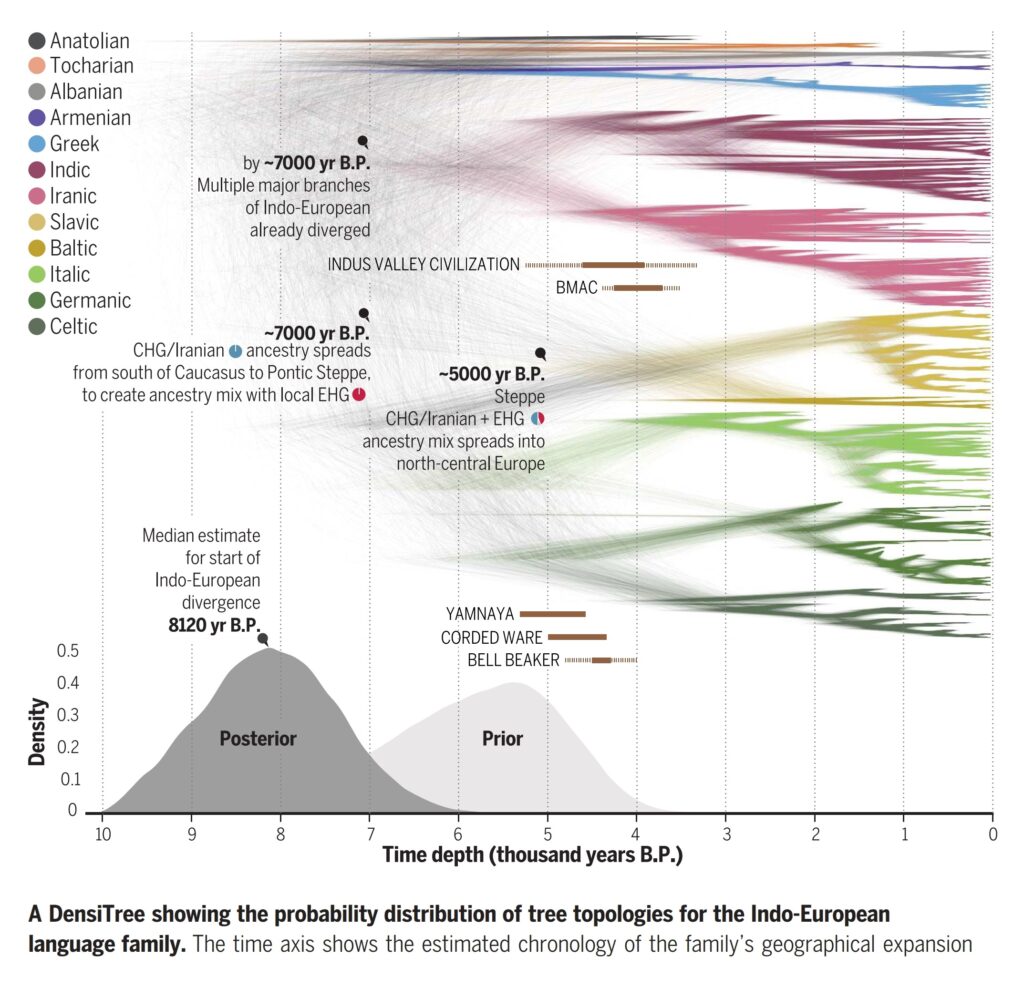
- Did the speakers of Proto-Indo-European already have the technology of the wheel, and domesticated horses? If so, then our root date of c. 8120 BP would be too early, since these developments only came about a couple of millennia later. The idea that reconstructions of the Proto-Indo-European stage of the language lineage supposedly prove knowledge of the wheel and horse domestication is based on a claimed inference technique known as ‘linguistic palaeontology’: see Box 1 in the main paper, and for more details, section 2.2.1 of the supplement. There we demonstrate in particular that although this claim about the wheel and the domesticated horse has been very widely invoked by advocates of the Steppe hypothesis, it has also always been explicitly challenged by a number of Indo-Europeanists and historical linguists, who from the same Indo-European language data conclude instead that Proto-Indo-European must pre-date rather than post-date the wheel and wagon. There is likewise no reliable inference in Proto-Indo-European that horses were already domesticated. See also Heggarty (2018), Clackson (2013) and Mallory (2021), among others.
- Reconstructions of early stages of the Uralic language family include words that are often claimed to be loanwords into Uralic, borrowed from some contemporaneous form of Indo-European. If it is also interpreted that these words are of such a form, phonetically, that they could only possibly have originated specifically in the Indo-Iranic branch, which would thus place that branch on or near the Steppe, near to where Uralic may have orginated. There are, however, many assumptions and uncertainties surrounding these claims. For discussion, see Box 1 in the main paper, and section 2.2.2 of the supplement.
- Did the Indo-Iranic and Balto-Slavic branches remain together for longer than other main branches, as a joint, late Indo-Iranic+Balto-Slavic ‘mega-branch’ of the Indo-European family? If so, then since Balto-Slavic is taken to have originated on the Steppe, Indo-Iranic must have originated there too. We address this in Box 1 in the main paper, and much more fully in the supplement in section 7.6. In section 7.6.2.1 in particular, we discuss two of the main language data characters argued to support it: Ringe’s (2002) variant of the centum/satem distinction (excluding Armenian), and the ’ruki rule’. We also performed our supplementary analysis SA6b (section 7.6.2) to test the effect on our root date estimate of enforcing a tree structure for the Indo-European family that does include this node (Ringe 2002).
- Was the Indo-Iranic branch intrusive into India and Iran (and neighbouring countries) from the Steppe/Central Asia, at a relatively late date? Supporters of the Steppe hypothesis have usually argued that this date could be no earlier than the collapse of the Indus Valley Civilisation (IVC) c. 3800 BP, because they also assume that the people of the IVC did not speak Indo-Iranic (itself a controversial assumption, particularly in India itself). We address this controversy in section 4.12, and recommend Bryant (2001) for a very extensive and balanced discussion of the debate. (Note that there has been controversy in archaeology too, since the material culture record in India or Iran does not show significant intrusion from Central Asia at this time-depth.)
- Related to this: How old are Vedic Sanskrit and Avestan? It is not firmly known, and hotly disputed, how long ago the Vedas and Avesta were first composed. The issue is because they were first composed orally, not in writing, and indeed were passed down orally for centuries before they were first committed to writing — and in any case, none of those earliest manuscripts survive either. We address this in section 4.12, and again recommend Bryant (2001). Reflecting the uncertainty and different proposals on their datings, we set our time calibrations for these two languages to be particularly broad, although with most of the distribution centred on the majority view. Our main analysis in any case returned estimated dates for both languages in line with that majority view. We also performed our sensitivity analysis SA1 (section 7.1) to remove explicit date calibrations for these languages entirely, and thus to let their time-depths be estimated by the method, within the family tree as a whole — relative to all 50 other historical languages in IE-CoR that are more firmly dated by surviving texts. Again, in SA1 too the dates estimated for Vedic and Avestan remained in line with majority view.
- Related in turn: How similar are Vedic Sanskrit and Avestan to each other? We take this up on page 4 of our article. Since language change is cumulative over time, it is a general principle that the more similar two related languages are, the shorter the time-span over which they have been diverging — but this is far from a strictly proportional relationship, since there is great variation in actual rates of change over time. Hitherto, impressions have generally been that Vedic and Avestan are similar enough that they might only have been diverging from each other for a matter of centuries (to fit with the assumption that Indo-Iranic came through Central Asia and only arrived in India and Iran relatively late, see points 4 and 5 above). Our results estimate that Vedic and Avestan have been diverging for much longer than just a few centuries, however. Indeed this is simply a logical and expected outcome from the data for these languages in the IE-CoR dataset, because in the precise IE-CoR reference meanings Early Vedic and Younger Avestan do not in fact share a particularly high proportion of cognates, as can be consulted for these two languages compared here on IE-CoR. The lexeme and cognate determinations for these languages in IE-CoR were performed independently by established experts on them, Roland Pooth and Thomas Jügel respectively, and cross-checked by Martin Joachim Kümmel. For information, the actual figure for shared cognacy between these languages is 58.7% across the IE-CoR reference meaning set, about the same as between the most divergent languages within the Romance branch, diverging for roughly two millennia since the Roman Empire. (These figures are mentioned here for indicative and comparative purposes only; such raw percentage counts have no role in our phylogenetic analyses, and are explicitly not what our chronology is inferred from. Our method has nothing to do with the rightly discredited old technique of lexicostatistics or glottochronology. We use not simple statistics but modelling, of language descent along branching tree structures through time, which moreover does not assume any fixed rate of change, long known to be empirically false. For how our chronological estimation works, see section 5.3.)
On Bayesian phylogenetic methods, controversies surround in particular …
- Whether cognate relationships as a language data type are valid for accurately establishing language family trees. We address this in sections 3.9 and 7.11.3, and performed SA6a (section 7.6.1) to constraint the phylogenetic results to established classifications based on phonological and morphological criteria that are taken to be diagnostic of tree topology.
- Whether similarities between ancient Indo-European languages in morphology and phonology are still so close that our early root date estimate would entail implausibly slow rates of change in morphology and phonology. We discuss this in section 2.2.3.
- Whether loanwords, because they represent horizontal rather than vertical inheritance, represent a confound that undermines the ability of these methods to infer chronology. We address this in section 3.8, and perform SA2 (section 7.2) to test the effects of alternative approaches to coding loanwords of different types. In section 8.1 we identify other contact effects that may also disrupt inference of close language relationships, and report parts of our phylogeny where we suspect this.
- Whether to constrain direct ancestry relationships between given ancient and modern language taxa. This hangs on the general issue of what ’language’ taxa actually represent in cognate databases and phylogenetic analyses, which we address in section 3.3, and in our assessment of our phylogeny results in sections 8.2 and 8.3. Moreover, unlike previous studies we use an ancestry-enabled form of phylogenetic analysis, which does not assume but tests for itself whether relationships were absolutely direct. We present this method in section 5.2 and report the results in section 6.2. We nonetheless also perfomed SA7a, SA7b and SA7c (section 7.7) to constrain various sets of hypothetical direct ancestry relationships. We also performed SA8(section 7.8) to test the impact of such constraints with different data-sets, partly reproducing the ancestry-constrained analysis in Chang et al. (2015) on the old IELex data‑set, in contrast to our new IE-CoR dataset. Further discussion of the effects of enforcing direct ancestry can be found in Heggarty (2021).
On which ancestries in ancient DNA may correspond to which branches of Indo-European languages, there have also been conflicting proposals and arguments, especially on the following issues.
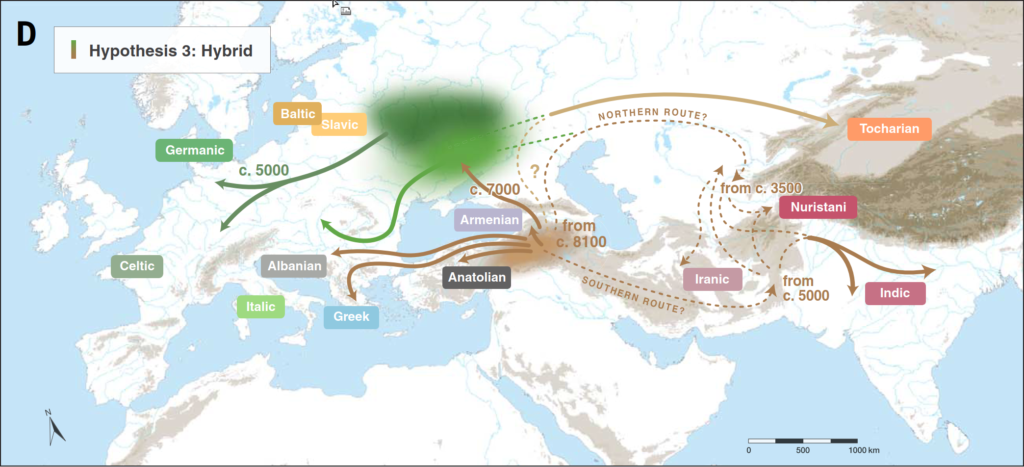
- The original Steppe hypothesis is named for the Steppe — or to be more precise, the Pontic-Caspian Steppe, i.e. the steppe grasslands immediately north of the Black Sea, Caucasus, and Caspian Sea — as the hypothesised homeland of the entire Indo-European family, i.e. the source of all its branches (see Box 2 and Box 3 in our article, and section 2.1.3 in the supplement). Necessarily, this explicitly included the Anatolian branch of the family, hypothesised to have spread from the Steppe to Anatolia through the Balkans (e.g. Anthony & Ringe 2015: Fig. 2). Ancient DNA sampling sought genetic evidence of such a migration through the Balkans, but ended up not finding support for it (Mathieson et al. 2018: 201). Sampling from archaeological contexts in Anatolia directly associated with the Hittites (i.e. speakers of the main attested language of the Anatolian branch of Indo-European) also found that the ancestry mix typical of the Yamnaya culture on the Pontic-Caspian Steppe was in fact notable for its absence (Damgaard et al. 2018, Lazaridis et al. 2022). The conclusion generally drawn is that the Anatolian branch did not originate on the steppe, but south of the Caucasus (see Lazaridis et al. 2022, Heggarty 2022). See also section 2.1.4 in the supplement.
- How and when did the Indo-Iranic branch of Indo-European languages reach India, Iran and neighbouring countries? Did they take a route north of the Caspian Sea, or south of it? That is, did Indo-Iranic arrive relatively late (c. 3500 BP) by a migration through Central Asia, ultimately out of the Pontic-Caspian Steppe (a ‘northern’ route)? Or did Indo-Iranic spread earlier, directly from the northern Fertile Crescent, through what is today Iran (a ‘southern’ route)? We illustrate both hypothesised routes in our Figure 1D, and address this on page 9 of the article, and more extensively in section 2.1.5 of the supplement. To summarise: perspectives from ancient DNA have been various, in support of one or other route. One complicating issue is that in much of South Asia, climatic conditions are generally poor for the preservation of aDNA, so relatively few samples have been successfully recovered yet from India and Pakistan. Jones et al. (2015) and Broushaki et al. (2016) see in the dominant ancestries of speakers of Indo-Iranic a direct origin primarily from south of the Caucasus, without passing through the Steppe. Ancient DNA sampled from urban contexts of the BMAC culture (Narasimhan et al. 2019), often equated with speakers of the (Indo-)Iranic branch of Indo-European, also shows predominantly this ancestry, and still no influx of ancestry from the Steppe (via Central Asia). That is ultmately found, at generally low proportions, from c. 3500 BP in the Swat Valley in northernmost Pakistan (Narasimhan et al. 2019). Analyses of these data, and of one genome recovered from the context of the Indus Valley Civilisation (Shinde et al. 2019), were initially argued to exclude a southern route for Indo-Iranic, but those analyses are now considered superseded by improved methodology which does not in fact exclude that route (Maier et al. 2023). Currently, debate still seems unresolved, with no consensus.
10. Further Reading
Coming soon …
11. All 33 Authors
Coming soon: links to personal homepages …
Paul Heggarty
Cormac Anderson
Matthew Scarborough
Benedict King
Remco Bouckaert
Lechosław Jocz
Martin Joachim Kümmel
Thomas Jügel
Britta Irslinger
Roland Pooth
Henrik Liljegren
Richard F. Strand
Geoffrey Haig
Martin Macák
Ronald I. Kim
Erik Anonby
Tijmen Pronk
Oleg Belyaev.
Tonya Kim Dewey-Findell
Matthew Boutilier
Cassandra Freiberg
Robert Tegethoff
Matilde Serangeli
Nikos Liosis
Krzysztof Stroński
Kim Schulte
Ganesh Kumar Gupta
Wolfgang Haak
Johannes Krause
Quentin D. Atkinson
Simon J. Greenhill
Denise Kühnert
Russell D. Gray