

Indo-European Origins: Language, Family Trees, Archaeology and Genetics
Half the world today speaks native languages that all belong to the same family: Indo-European. You are reading in one of these languages now: English is Indo-European — in other words, it is related, either closely or more distantly, to hundreds more languages from Iceland to Bengal. Over many thousands of years, these languages have grown far apart from each other, but all had started out as what was once the same single ancestor language, ‘Proto-Indo‑European’. By today, its panoply of daughter languages has changed and diverged so radically that little obvious is left of their once common origin, although surviving traces can still be heard in the numbers up to ten, for example, and some other basic words. To listen and compare these words across languages of the four main branches of Indo-European within Europe (i.e. Celtic, Romance, Germanic and Slavic), visit: soundcomparisons.com/Europe.
Linguistics was born with this realisation that all these languages, including also ancient Greek, Latin, Sanskrit and Avestan, are ultimately “sprung from some common source”. Over two centuries of research, linguists have been able to ‘reconstruct’ a great deal about the original Proto-Indo‑European language itself. But trying to pin down where and when it was spoken, deep in prehistory, has relied on inferences that are far less reliable and conclusive, and more subjective. In the 19th and early 20th centuries, ‘Aryan’ studies became mired in racist and supremacist ideologies, and fanciful, anachronistic visions of prehistory. The leading serious, realistic modern hypotheses are rooted above all in archaeology, and since 2015 ancient DNA has revolutionised our understanding of population expansions across Europe and parts of Asia, bringing us ever closer to a resolution of the Indo-European origins question.
Indo-European is still essentially a linguistic entity, however, so the direct data lie in the languages themselves. Can more can be made of them, though, with new computational tools? Powerful software now exists for modelling the processes by which family tree structures can arise, and even estimating a timeframe for how they diverged. These tools were devised originally for modelling such ‘evolutionary’ processes in biology, but language families also come about by ‘descent with modification’, so in principle the same general approach should be viable.
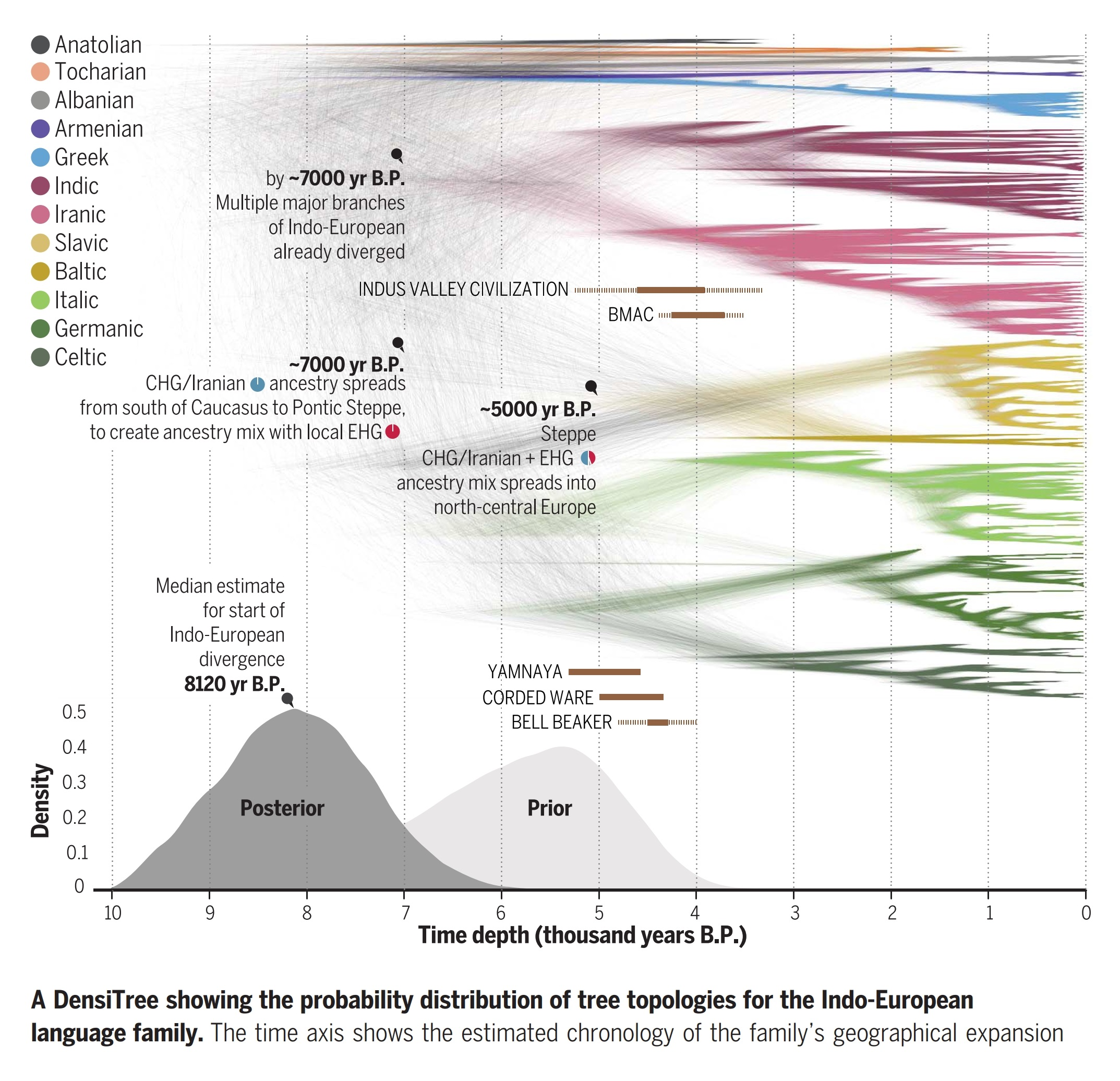
Nonetheless, when the latest ‘Bayesian phylogenetic modelling’ was first applied to Indo-European, different studies threw up conflicting results. On closer inspection (Heggarty 2021), those first results included obvious artefacts, and the cause could be traced back to how the basic language data used had been handled inconsistently, when they were encoded in binary terms as input to the phylogenetic modelling. A new methodology was needed, to create a completely new language database. One type of language data is particularly viable for these Bayesian phylogenetic analyses, and especially for estimating chronology: the patterns in how some ancient word roots (‘cognates’) survive or have shifted meaning, across the different branches of the Indo-European family. Over five years I led a team of over 90 language experts, with my co-editors Dr Cormac Anderson and Dr Matthew Scarborough, to create IE‑CoR, the new Indo-European Cognate Relationships database, published as nature.com/articles/s41597-025-05445-3 and free to explore online at iecor.clld.org.
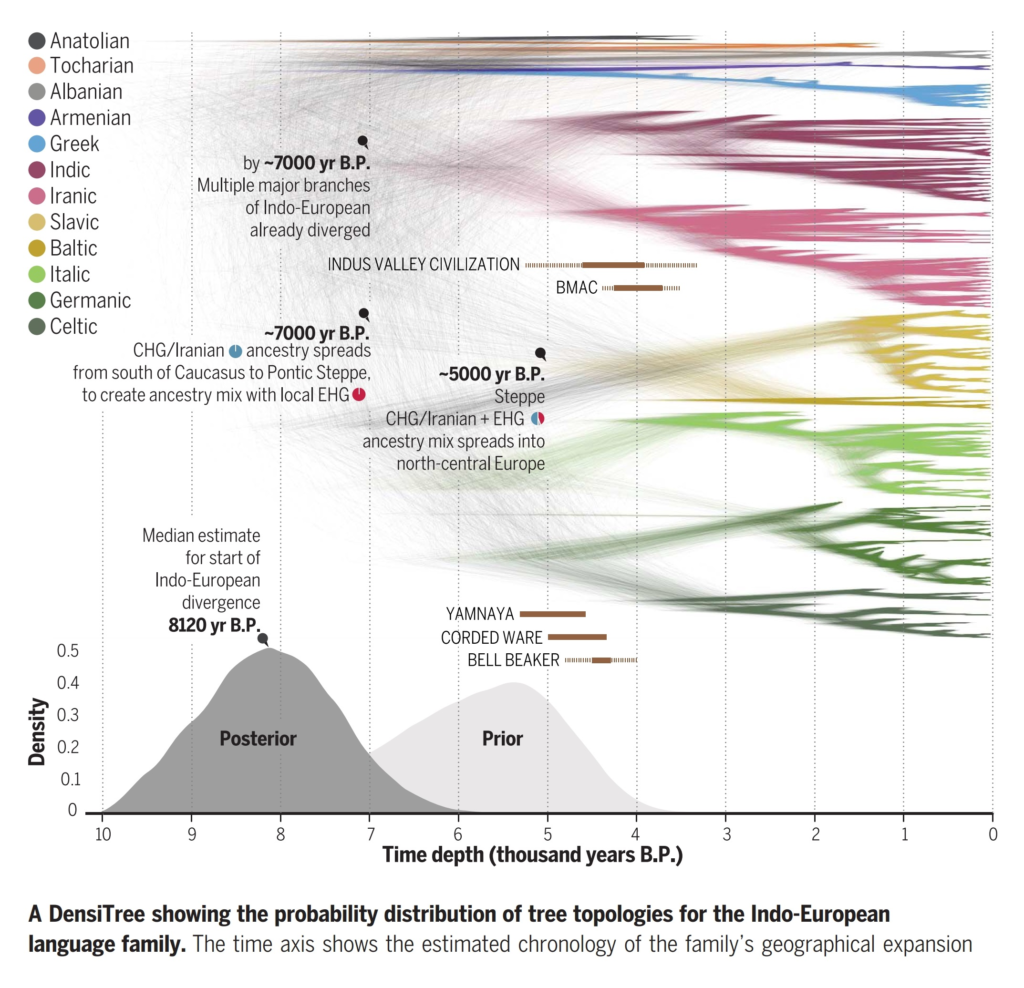
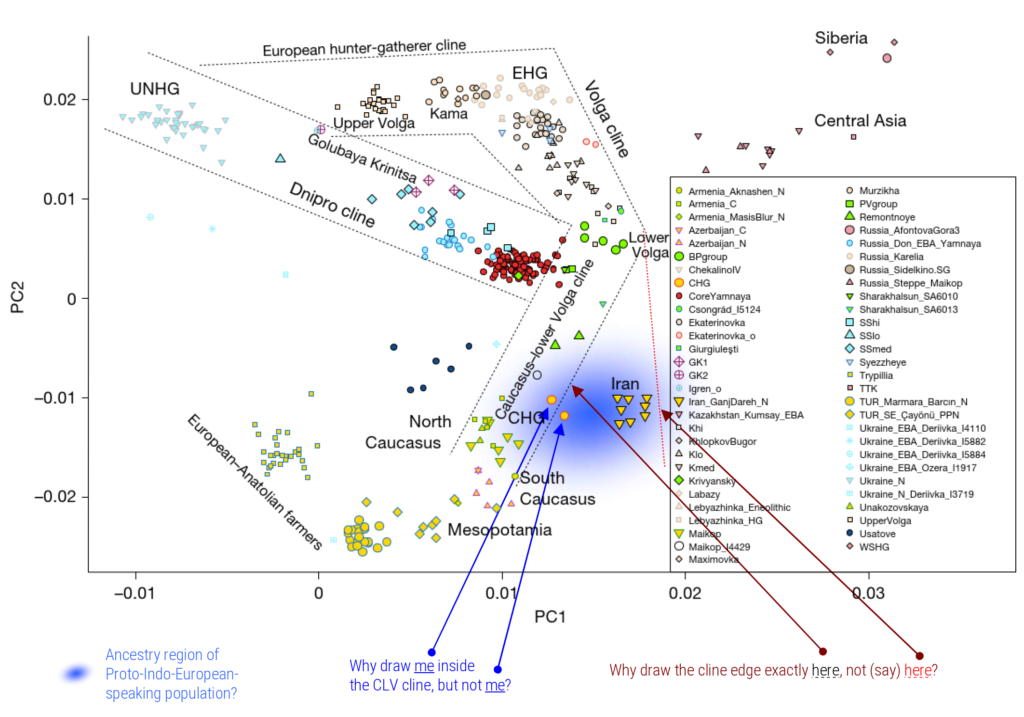
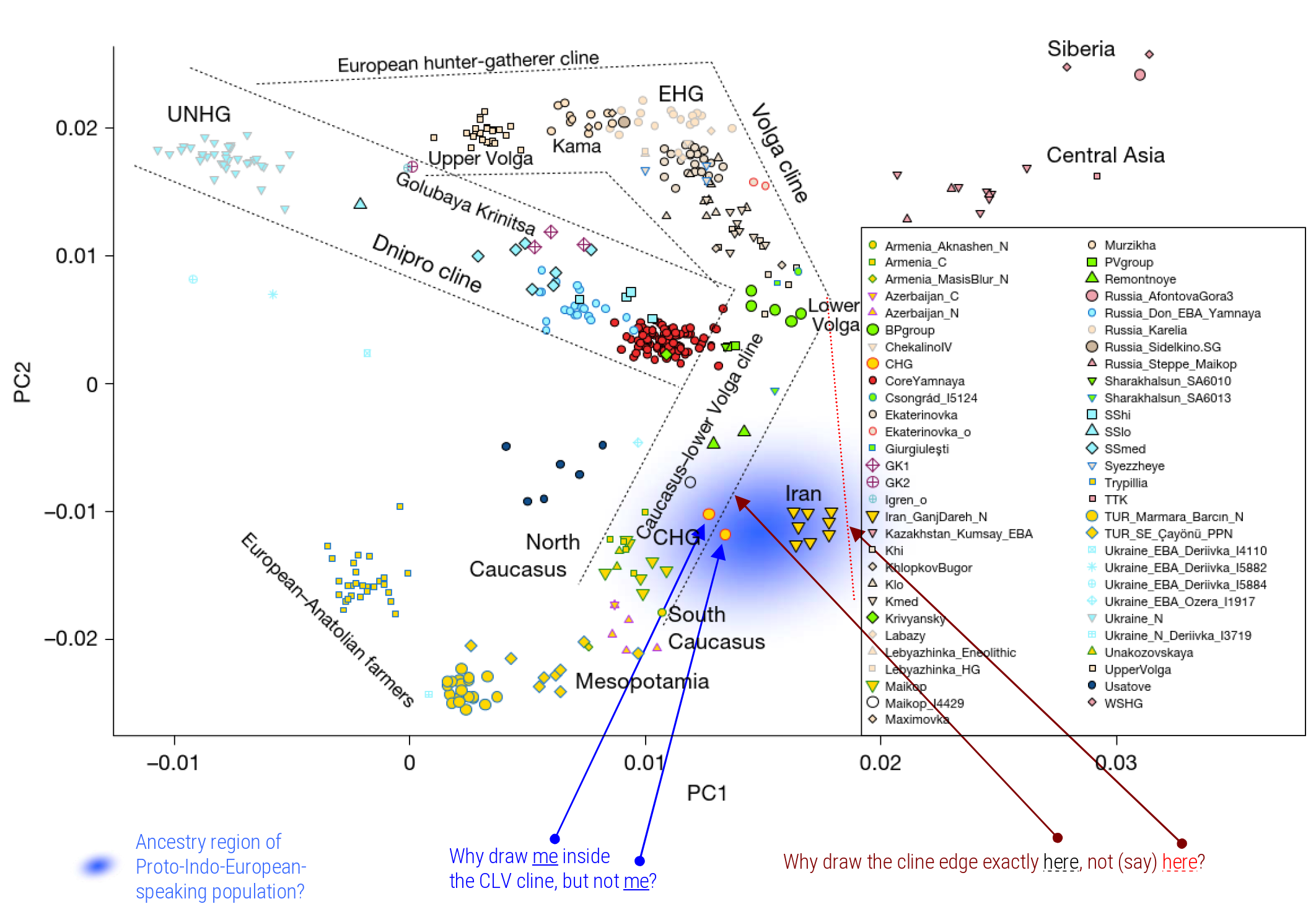
IE‑CoR was the input data to a new Bayesian phylogenetic analysis of the Indo-European family in Science (Heggarty et al. 2023). This returned a time estimate that Indo-European first began (spreading and) diverging just over 8000 years ago, and seven major branches had already emerged by c. 7000 years ago. This chronology, and the branching sequence of the tree, are not compatible with the predominant ‘Steppe hypothesis’ of Indo-European origins, but fit with archaeological and ancient DNA evidence into a more plausible overall scenario. The ultimate origins of all Indo-European lay south of the Caucasus, in the northern arc of the Fertile Crescent. The Steppe north of the Black Sea was a plausible later staging post, but only for some of the European branches of the family, and not for Indo-Iranic. See also Press.
This Science paper fits into my long focus on all aspects of the Indo-European origins question, on research methods both within historical linguistics, and in concert with archaeology and genetics, including:
-
Bayesian phylogenetic analysis, and how to apply it specifically to language.
-
Pitfalls and solutions for encoding comparative language data consistently, and in binary form, as input for quantitative and modelling applications.
-
How historical linguistics needs to engage with an up-to-date understanding of actual prehistory. Early processes of domestication and technologies, in particular, serve as a reality check on outdated, superficial inferences from traditional ‘linguistic palaeontology’ about the presumed roles of the horse, wheel, wagons, metals, crops, etc..
-
The farming/language dispersals hypothesis, often misunderstood and overstated, which underlay one of two major hypotheses on Indo-European origins.
-
The flaws in forcing interpretations of genetic data into a presumption of the Steppe hypothesis for Indo-European origins. In fact, ancient DNA results support a steppe origin as only secondary, and only for some branches in Europe, while for other crucial branches, not least Anatolian, Greek and Indo-Iranic, ancient DNA undermines a steppe homeland, and points elsewhere.





{kind=link}
{kind=link}
{kind=link}
{kind=link}